

There is a lot of hype about the use of artificial intelligence (AI) in cybersecurity. The truth is that the role and potential of AI in security is still evolving and often requires experimentation and evaluation.
SophosAI is committed to openly sharing its data science research with the security community in order to make the use of AI more transparent and influence how AI is positioned and discussed in cybersecurity.
Details of other initiatives shared as part of this objective are available in the SophosAI blog.
Catastrophic forgetting: What is it?

Malware detection is the cornerstone of IT security and AI is the only approach capable of learning patterns from millions of new malware samples within a matter of days.
But there’s a catch: should the model keep all malware samples forever for optimum detection but slower learning and updates; or go for selective fine-tuning that enables the model to better keep up with the rate of change of malware, but runs the risk of forgetting older patterns (known as catastrophic forgetting)?

Retraining the whole model takes about one week. A good fine-turning model should take about one hour to update.
SophosAI wanted to see if it was possible to have a fine-tuning model that could keep up with the evolving threat landscape, learn new patterns but still remember older ones, while minimizing the impact on performance. Researcher Hillary Sanders evaluated a number of update options and has detailed her findings in the Sophos AI blog.
The detection dilemma
Keeping detection capabilities up to date is a constant battle. With every step we take towards defending against a malicious attack, adversaries are already developing new ways to get round it, releasing updates with different code or techniques. The result is that hundreds of thousands of new malware samples appear every day.
Detection is made even harder by the fact that the latest-and-greatest malware is rarely completely “new.” Instead, it is more likely to be a combination of new, old, shared, borrowed or stolen code and adopted and adapted behaviors. Further, old malware can re-emerge after years in the wilderness, co-opted into an adversary’s latest arsenal to take defenses by surprise.
Detection models need to ensure they can continue to detect older malware samples, and not just the most recent ones.
Updating AI detection models
When it comes to updating AI detection models with new malware samples, vendors have a choice between two options.
- The first is to keep a copy of every sample they might ever want to detect and retrain the model repeatedly on an ever-increasing volume of data. This results in better overall performance but also slower updates and fewer releases.
- The second is to only update the detection model on new samples. This is known as fine-tuning. During each step of the fine-tuning process, the model updates its understanding according to the new knowledge added and the impact of this on the patterns seen overall. As a result, the model can “forget” the old patterns it learned previously (“catastrophic forgetting”). However, training a model on less data means the model updates faster and can be released more frequently, keeping better pace with the rapid rate of change of malware.
Regardless of the option chosen, the need to keep training AI detection models on new samples is critical.
The patterns that AI learns from malware samples enable it to generalize and detect not only what it was trained on, but also never before seen samples that bear at least some resemblance to the training data. Over time, however, new samples will begin to deviate enough that an old model’s effectiveness will decay, and it will need to be updated.
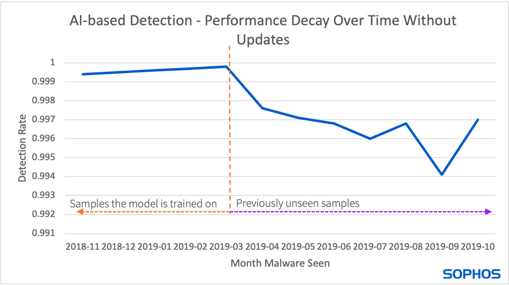
The following figure visualizes how detection performance declines over time if models are not updated when new samples appear. On the left are the older samples the model has been trained on. The detection rate is consistently strong. To the right are the new samples the model has not yet learned, so detection is weaker.
The three detection update options evaluated by Hillary Sanders were:
1.Learning based on a selection of old and new samples
This is called “data-rehearsal” and involves taking a small selection of old samples and mixing them in with the new, never-before-seen training data. Using this, the model is “reminded” of the old information it needed to detect older samples, while at the same time learning to detect the newer ones.
2.Learning Rate
This approach involves modifying how quickly the model “learns” by adjusting how much it can change after seeing any given sample. If the learning rate is too fast (in which case the model can change a lot with each sample added), it will only “remember” the most recent samples that it has seen. If the learning rate is too slow (the model can change only slightly with each sample added) it takes too long to learn anything. Finding the right trade-off between learning rate, retaining old information and adding new information can be tricky.
3.Elastic Weight Consolidation (EWC)
This approach was inspired by work by Google’s DeepMind in 2017, and it involves using the old model like an elastic spring to “pull back” the new model if it starts to “forget.” For a more in-depth explanation of how to implement this approach, read Hillary Sanders’ blog post.
Findings
All three approaches performed better on older malware samples (left of the dotted line) than on newer samples (right of the dotted line).
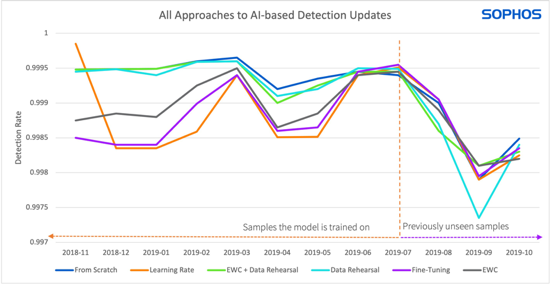
Both the EWC and learning-rate approaches remove the need and cost of maintaining older data. However, the graph shows that while their future performance (using new data) is stronger than that achieved using the data-rehearsal technique, they don’t perform as well as data-rehearsal when comes to remembering past data.
Because the data-rehearsal technique enables faster training and update releases – in other words, the performance moves more quickly from the ‘unseen’ to the ‘trained’ side of the chart, dips in future performance are more short term and therefore less worrying.
Overall, the research showed that the data-rehearsal approach offers the best compromise between simplicity, update speed and performance in malware detection modelling.
Conclusion
In the malware detection game, being able to remember the past is almost as important as being able to predict the future. This must be balanced against the cost and speed of updating your model with new information. Data-rehearsal is a simple and effective way to protect the model’s ability to detect old malware while significantly increasing the pace at which you can update and release new models.
Follow us on Telegram, Twitter, Facebook, or subscribe to our weekly newsletter to ensure you don’t miss out on any future updates. Send tips to info@techtrendske.co.ke.

